








 壹览商业
壹览商业出品/未来科技界
作者/张永堃
编辑/李彦
头图/微博@Google黑板报
在智能体AI(Agentic AI)浪潮下,谷歌正试图重新定义算力基础设施。
美国太平洋时间2026年4月22日9点,在Google Cloud Next大会上,谷歌正式发布其“AI超级计算机”(AI Hypercomputer),该架构整合了其自研第八代 TPU、Axion CPU 以及 NVIDIA 新一代 Rubin GPU,旨在为 Agentic AI 时代提供核心的底层算力支撑。

此次发布同时涉及第七代TPU“Ironwood”的全面商用(GA)以及第八代架构(TPU v8)的首次分化。这反映了谷歌在应对巨额资本支出压力时,正试图通过硬件深度特化来优化其云业务的边际利润。
作为目前的旗舰产品,第七代TPU Ironwood在核心参数上已实现直接对标英伟达Blackwell B200。Ironwood单芯片可提供4.6 PetaFLOPS的FP8峰值算力,配备192GB HBM3e内存。单个Superpod通过集成9,216颗芯片,可提供42.5 ExaFLOPS的总算力。
英伟达在单芯片互连带宽上保持领先,其NVLink 5技术可提供高达14.4 Tbps的双向带宽,而Ironwood的ICI带宽为9.6 Tbps。此外,英伟达Blackwell架构原生支持FP4精度,这使得量化模型在推理时的吞吐量能够实现翻倍,而Ironwood并不具备这一能力。
但Ironwood的核心卖点在于系统级效率——每瓦性能较前代提升2倍,且通过垂直整合的软件栈优化,显著降低推理成本。随着Ironwood在本次大会正式进入GA阶段,它已成为谷歌自研算力体系的中坚力量。
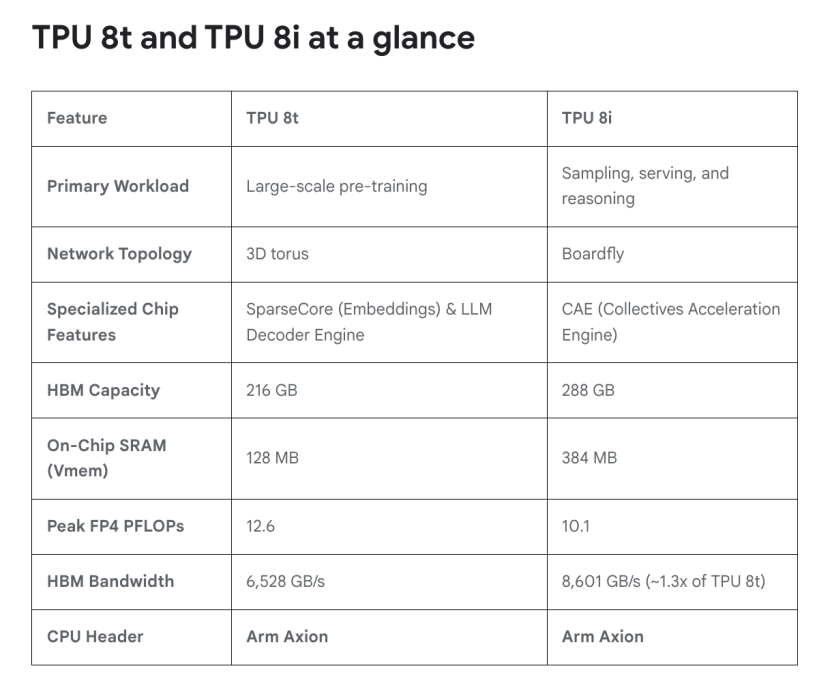
在Ironwood全面商用的同时,谷歌首次打破了TPU系列单一架构的传统,针对训练与推理两个不同的经济模型,推出了第八代TPU的两种特化版本:针对训练优化的TPU 8t 以及针对推理与Agentic AI优化的TPU 8i。
两款芯片均采用台积电2nm制程,目标于2027年末量产。这一架构拆分标志着AI算力工业化进入了“精细化阶段”—— 面对生成式 AI 带来的巨额成本压力,厂商必须通过硬件深层特化来榨取极限能效,必须通过硬件特化来优化每一美元的产出。

谷歌CEO桑达尔·皮查伊发帖称TPU v8两款芯片“看起来还不错”
面向训练的TPU 8t
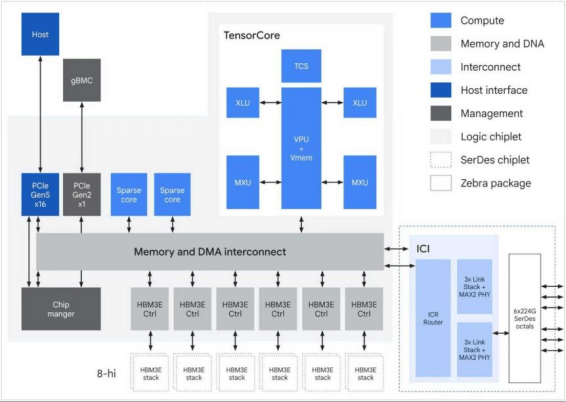
TPU 8t定位于训练领域的性能旗舰,旨在将前沿模型的部署时间从数月缩短至数周。该芯片由博通设计,单pod FP4算力达到121 Exaflops,较Ironwood提升2.84倍。
在集群能力上,TPU 8t支持单个Superpod扩展至9,600颗芯片,配备2PB共享高带宽内存,ICI带宽较上一代翻倍。
在存储与数据传输方面,TPU 8t通过将存储访问速度提升10倍,并结合TPUDirect技术绕过主机 CPU 实现数据直达HBM,显著提升了系统的整体利用率。依托Virgo网络以及JAX与Pathways软件栈,TPU 8t可实现近线性扩展,并支持在单一逻辑集群中扩展至最多百万颗芯片。
此外,据Data Center Dynamics报道,该芯片引入了原生FP4精度,在降低内存带宽瓶颈的同时减少数据传输能耗。综合来看,与Ironwood相比,TPU 8t在大规模训练场景下实现了约2.7倍的单位成本性能提升。
面向推理的TPU 8i
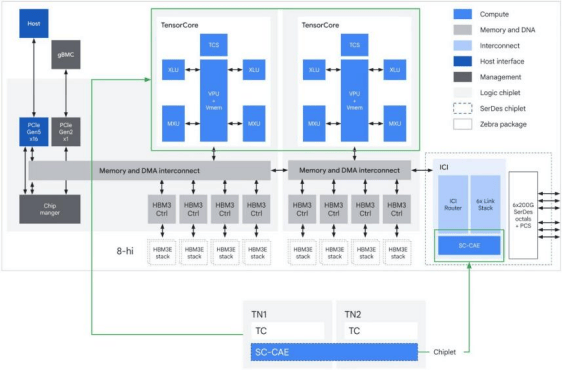
TPU 8i专注优化低延迟与高吞吐能力。该芯片由联发科设计,配备288GB HBM内存与384MB片上SRAM,片上容量较上一代提升3倍,使模型能够在芯片内部保持活跃状态。在架构优化方面,TPU 8i采用基于Arm架构的Axion CPU并结合NUMA架构提升性能。针对MoE模型,通过Boardfly架构将网络直径缩短超过50%。
TPU 8i通过片上CAE将部分全局操作卸载处理,使芯片内部延迟最高降低5倍。与Ironwood相比,TPU 8i在低延迟推理场景下实现约80%的单位成本性能提升。
两款芯片均实现约2倍的性能功耗提升,并支持谷歌第四代液冷技术。
谷歌在芯片战略上的“分而治之”,本质上是供应链定价权的重新配置。根据4月6日,博通向SEC提交的8-K文件,谷歌已与博通达成长期协议,将TPU合作延续至2031年,这就意味着博通将继续谷歌主导高性能训练芯片的物理实现。
与此同时,联发科则接管了成本敏感型推理芯片的设计工作,其方案相比替代选项成本低20%至30%。此外,Marvell正在与谷歌洽谈内存处理单元及另一款推理TPU的开发,预计设计定型于2027年完成。英特尔则提供Xeon处理器及定制IPU。
这种供应链重构的背后,是巨大的资本支出压力。谷歌预测2026年资本支出将达1750亿至1850亿美元,较2025年的914亿美元几乎翻番。这种规模的投入要求谷歌必须通过自研芯片来规避外购GPU的“品牌溢价”。
自研TPU的核心商业逻辑正在于此:在推理规模持续扩大的背景下,定制ASIC的经济模型优于通用GPU。TrendForce预测2026年定制AI芯片销售增长45%,而GPU出货量仅增长16%,行业共识正在形成。
在单点硬件突破之外,谷歌更大的野心在于系统级整合。AI超级计算机的核心在于统一计算、存储、网络、软件及机器学习框架,构建一套高度集成的高性能架构。谷歌的策略清晰可见:利用英伟达维持生态多样性,利用自研TPU守住核心业务的利润率。
目前,这一超级计算机体系已经获得了关键客户的认可。Anthropic已成为谷歌自研算力体系的战略锚定客户。据DataCenterNews报道,Anthropic已签署协议至2027年,协议包括3.5吉瓦的TPU算力资源,其2026年收入运行率已突破300亿美元,对底层算力的性价比极其敏感,这正是谷歌自研推理芯片的核心价值主张。
TPU v8的拆分发布,标志着AI算力工业化进入了精细化阶段。对于谷歌而言,AI的下半场竞争不再仅仅是比拼谁的算力更高,而是比拼谁能让每一美金的投入产生更高的推理产出。在2nm制程与3.5吉瓦电力规模的博弈中,谷歌正在通过构建闭环的“AI超级计算机”生态,从底层硬件端完成对AI定价权的掌控。
AI的下半场,算力不再是唯一壁垒——每美元产出效率才是真正的护城河。